Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Хочу продолжить серию статей посвященных различным терминам, которые не всегда могут быть понятны без дополнительных пояснений. Чуть ранее я рассказывал про то, что значит слово кликбейт и что такое хост, писал про IP и MAC адреса, фишинг и многое другое.

Сегодня у нас на очереди хеш. Что это такое? Зачем он нужен? Почему это слово так часто используется в интернете применительно к совершенно разным вещам? Имеет ли это какое-то отношение к хештегам или хешссылкам? Где применяют хэш, как вы сами можете его использовать? Что такое хэш-функция и хеш-сумма? Причем тут коллизии?
Все это (или почти все) вы узнаете из этой маленькой заметки. Поехали.
Появился этот термин в середине прошлого века среди людей занимающихся обработках массивов данных. Хеш-функция позволяла привести любой массив данных к числу заданной длины. Например, если любое число (любой длинны) начать делить много раз подряд на одно и то же простое число, то полученный в результате остаток от деления можно будет называть хешем. Для разных исходных чисел остаток от деления (цифры после запятой) будет отличаться.
Для обычного человека это кажется белибердой, но как ни странно в наше время без хеширования практически невозможна работа в интернете. Так что же это такая за функция? На самом деле она может быть любой (приведенный выше пример это не есть реальная функция — он придуман мною чисто для вашего лучшего понимания принципа). Главное, чтобы результаты ее работы удовлетворяли приведенным ниже условиям.
Смотрите, еще пример. Есть у вас текст в файле. Но на самом деле это ведь не текст, а массив цифровых символов (по сути число). Как вы знаете, в компьютерной логике используются двоичные числа (ноль и единица). Они запросто могут быть преобразованы в шестнадцатиричные цифры, над которыми можно проводить математические операции. Применив к ним хеш-функцию мы получим на выходе (после ряда итераций) число заданной длины (хеш-сумму).
Если мы потом в исходном текстовом файле поменяем хотя бы одну букву или добавим лишний пробел, то повторно рассчитанный для него хэш уже будет отличаться от изначального (вообще другое число будет). Доходит, зачем все это нужно? Ну, конечно же, для того, чтобы понять, что файл именно тот, что и должен быть. Это можно использовать в целом ряде аспектов работы в интернете и без этого вообще сложно представить себе работу сети.
Например, простые хэш-функции (не надежные, но быстро рассчитываемые) применяются при проверке целостности передачи пакетов по протоколу TCP/IP (и ряду других протоколов и алгоритмов, для выявления аппаратных ошибок и сбоев — так называемое избыточное кодирование). Если рассчитанное значение хеша совпадает с отправленным вместе с пакетом (так называемой контрольной суммой), то значит потерь по пути не было (можно переходить к следующему пакету).
А это, ведь на минутку, основной протокол передачи данных в сети интернет. Без него никуда. Да, есть вероятность, что произойдет накладка — их называют коллизиями. Ведь для разных изначальных данных может получиться один и тот же хеш. Чем проще используется функция, тем выше такая вероятность. Но тут нужно просто выбирать между тем, что важнее в данный момент — надежность идентификации или скорость работы. В случае TCP/IP важна именно скорость. Но есть и другие области, где важнее именно надежность.
Похожая схема используется и в технологии блокчейн, где хеш выступает гарантией целостности цепочки транзакций (платежей) и защищает ее от несанкционированных изменений. Благодаря ему и распределенным вычислениям взломать блокчен очень сложно и на его основе благополучно существует множество криптовалют, включая самую популярную из них — это биткоин. Последний существует уже с 2009 год и до сих пор не был взломан.
Более сложные хеш-функции используются в криптографии. Главное условие для них — невозможность по конечному результату (хэшу) вычислить начальный (массив данных, который обработали данной хеш-функцией). Второе главное условие — стойкость к коллизиями, т.е. низкая вероятность получения двух одинаковых хеш-сумм из двух разных массивов данных при обработке их этой функцией. Расчеты по таким алгоритмам более сложные, но тут уже главное не скорость, а надежность.
Так же хеширование используется в технологии электронной цифровой подписи. С помощью хэша тут опять же удостоверяются, что подписывают именно тот документ, что требуется. Именно он (хеш) передается в токен, который и формирует электронную цифровую подпись. Но об этом, я надеюсь, еще будет отдельная статья, ибо тема интересная, но в двух абзацах ее не раскроешь.
Для доступа к сайтам и серверам по логину и паролю тоже часто используют хеширование. Согласитесь, что хранить пароли в открытом виде (для их сверки с вводимыми пользователями) довольно ненадежно (могут их похитить). Поэтому хранят хеши всех паролей. Пользователь вводит символы своего пароля, мгновенно рассчитывается его хеш-сумма и сверяется с тем, что есть в базе. Надежно и очень просто. Обычно для такого типа хеширования используют сложные функции с очень высокой криптостойкостью, чтобы по хэшу нельзя было бы восстановить пароль.
Хочу систематизировать кое-что из уже сказанного и добавить новое.
- Как уже было сказано, функция эта должна уметь приводить любой объем данных (а все они цифровые, т.е. двоичные, как вы понимаете) к числу заданной длины (по сути это сжатие до битовой последовательности заданной длины хитрым способом).
- При этом малейшее изменение (хоть на один бит) входных данных должно приводить к полному изменению хеша.
- Она должна быть стойкой в обратной операции, т.е. вероятность восстановления исходных данных по хешу должна быть весьма низкой (хотя последнее сильно зависит от задействованных мощностей)
- В идеале она должна иметь как можно более низкую вероятность возникновения коллизий. Согласитесь, что не айс будет, если из разных массивов данных будут часто получаться одни и те же значения хэша.
- Хорошая хеш-функция не должна сильно нагружать железо при своем исполнении. От этого сильно зависит скорость работы системы на ней построенной. Как я уже говорил выше, всегда имеется компромисс между скорость работы и качеством получаемого результата.
- Алгоритм работы функции должен быть открытым, чтобы любой желающий мог бы оценить ее криптостойкость, т.е. вероятность восстановления начальных данных по выдаваемому хешу.
Где еще можно встретить применение этой технологии? Наверняка при скачивании файлов из интернета вы сталкивались с тем, что там приводят некоторые числа (которые называют либо хешем, либо контрольными суммами) типа:
Что это такое? И что вам с этим всем делать? Ну, как правило, на тех же сайтах можно найти пояснения по этому поводу, но я не буду вас утруждать и расскажу в двух словах. Это как раз и есть результаты работы различных хеш-функций (их названия приведены перед числами: CRC32, MD5 и SHA-1).
Зачем они вам нужны? Ну, если вам важно знать, что при скачивании все прошло нормально и ваша копия полностью соответствует оригиналу, то нужно будет поставить на свой компьютер программку, которая умеет вычислять хэш по этим алгоритмам (или хотя бы по некоторым их них).
- CRC32 — используется именно для создания контрольных сумм (так называемое избыточное кодирование). Данная функция не является криптографической. Есть много вариаций этого алгоритма (число после CRC означает длину получаемого хеша в битах), в зависимости от нужной длины получаемого хеша. Функция очень простая и нересурсоемкая. В связи с этим используется для проверки целостности пакетов в различных протоколах передачи данных.
- MD5 — старая, но до сих пор очень популярная версия уже криптографического алгоритма, которая создает хеш длиной в 128 бит. Хотя стойкость этой версии на сегодняшний день и не очень высока, она все равно часто используется как еще один вариант контрольной суммы, например, при скачивании файлов из сети.
- SHA-1 — криптографическая функция формирующая хеш-суммы длиной в 160 байт. Сейчас идет активная миграция в сторону SHA-2, которая обладает более высокой устойчивостью, но SHA-1 по-прежнему активно используется хотя бы в качестве контрольных сумм. Но она так же по-прежнему используется и для хранения хешей паролей в базе данных сайта (об этом читайте выше).
- ГОСТ Р 34.11-2012 — текущий российский криптографический (стойкий к взлому) алгоритм введенный в работу в 2013 году (ранее использовался ГОСТ Р 34.11-94). Длина выходного хеша может быть 256 или 512 бит. Обладает высокой криптостойкостью и довольно хорошей скоростью работы. Используется для электронных цифровых подписей в системе государственного и другого документооборота.
Раз уж зашла речь о программе для проверки целостности файлов (расчета контрольных сумм по разным алгоритмам хеширования), то тут, наверное, самым популярным решением будет HashTab.
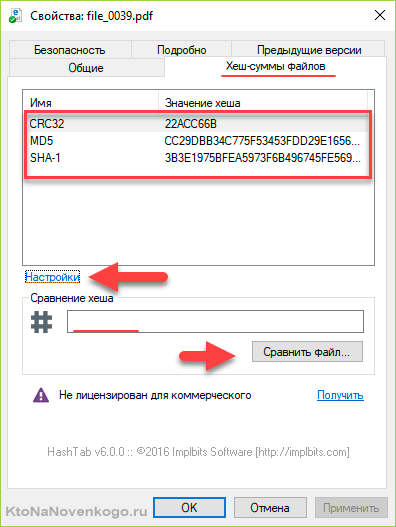
Как видите, все очень просто и быстро. А главное эффективно.
Несложные, крайне быстрые и легко реализуемые аппаратно алгоритмы, используемые для защиты от непреднамеренных искажений, в том числе ошибок аппаратуры.
По скорости вычисления в десятки и сотни раз быстрее, чем криптографические хеш-функции, и значительно проще в аппаратной реализации.
Платой за столь высокую скорость является отсутствие криптостойкости — легкая возможность подогнать сообщение под заранее известную сумму. Также обычно разрядность контрольных сумм (типичное число: 32 бита) ниже, чем криптографических хешей (типичные числа: 128, 160 и 256 бит), что означает возможность возникновения непреднамеренных коллизий.
Простейшим случаем такого алгоритма является деление сообщения на 32- или 16- битные слова и их суммирование, что применяется, например, в TCP/IP.
Среди множества существующих хеш-функций принято выделять криптографически стойкие, применяемые в криптографии. Криптостойкая хеш-функция прежде всего должна обладать стойкостью к коллизиям двух типов:
- Стойкость к коллизиям первого рода: для заданного сообщения

должно быть практически невозможно подобрать другое сообщение
, имеющее такой же хеш. Это свойство также называется необратимостью хеш-функции. - Стойкость к коллизиям второго рода: должно быть практически невозможно подобрать пару сообщений
, имеющих одинаковый хеш.
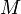
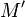
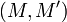
Согласно парадоксу о днях рождения, нахождение коллизии для хеш-функции с длиной значений n бит требует в среднем перебора около 2 n / 2 операций. Поэтому n-битная хеш-функция считается криптостойкой, если вычислительная сложность нахождения коллизий для нее близка к 2 n / 2 .
Простейшим (хотя и не всегда приемлемым) способом усложнения поиска коллизий является увеличение разрядности хеша, например, путем параллельного использования двух или более различных хеш-функций.
Для криптографических хеш-функций также важно, чтобы при малейшем изменении аргумента значение функции сильно изменялось. В частности, значение хеша не должно давать утечки информации даже об отдельных битах аргумента. Это требование является залогом криптостойкости алгоритмов шифрования, хеширующих пользовательский пароль для получения ключа.
Хеш-функции также используются в некоторых структурах данных — хеш-таблицаx и декартовых деревьях. Требования к хеш-функции в этом случае другие:
- хорошая перемешиваемость данных
- быстрый алгоритм вычисления
В общем случае это применение можно описать, как проверка некоторой информации на идентичность оригиналу, без использования оригинала. Для сверки используется хеш-значение проверяемой информации. Различают два основных направления этого применения:
Например, контрольная сумма может быть передана по каналу связи вместе с основным текстом. На приёмном конце, контрольная сумма может быть рассчитана заново и её можно сравнить с переданным значением. Если будет обнаружено расхождение, то это значит, что при передаче возникли искажения и можно запросить повтор.
Бытовым аналогом хеширования в данном случае может служить приём, когда при переездах в памяти держат количество мест багажа. Тогда для проверки не нужно вспоминать про каждый чемодан, а достаточно их посчитать. Совпадение будет означать, что ни один чемодан не потерян. То есть, количество мест багажа является его хеш-кодом.
В большинстве случаев парольные фразы не хранятся на целевых объектах, хранятся лишь их хеш-значения. Хранить парольные фразы нецелесообразно, так как в случае несанкционированного доступа к файлу с фразами злоумышленник узнает все парольные фразы и сразу сможет ими воспользоваться, а при хранении хеш-значений он узнает лишь хеш-значения, которые не обратимы в исходные данные, в данном случае в парольную фразу. В ходе процедуры аутентификации вычисляется хеш-значение введённой парольной фразы, и сравнивается с сохранённым.
Примером в данном случае могут служить ОС GNU/Linux и Microsoft Windows XP. В них хранятся лишь хеш-значения парольных фраз из учётных записей пользователей.
Например, при записи текстовых полей в базе данных может рассчитываться их хеш код и данные могут помещаться в раздел, соответствующий этому хеш-коду. Тогда при поиске данных надо будет сначала вычислить хеш-код текста и сразу станет известно, в каком разделе их надо искать, то есть, искать надо будет не по всей базе, а только по одному её разделу (это сильно ускоряет поиск).
Бытовым аналогом хеширования в данном случае может служить помещение слов в словаре по алфавиту. Первая буква слова является его хеш-кодом, и при поиске мы просматриваем не весь словарь, а только нужную букву.
Студент кафедры информационной безопасности.
Хэш-функцией называется всякая функция h:X -> Y, легко вычислимая и такая, что для любого сообщения M значение h(M) = H (свертка) имеет фиксированную битовую длину. X — множество всех сообщений, Y — множество двоичных векторов фиксированной длины.
Как правило хэш-функции строят на основе так называемых одношаговых сжимающих функций y = f(x1, x2) двух переменных, где x1, x2 и y — двоичные векторы длины m, n и n соответственно, причем n — длина свертки, а m — длина блока сообщения.
Для получения значения h(M) сообщение сначала разбивается на блоки длины m (при этом, если длина сообщения не кратна m то последний блок неким специальным образом дополняется до полного), а затем к полученным блокам M1, M2. MN применяют следующую последовательную процедуру вычисления свертки:
Здесь v — некоторая константа, часто ее называют инициализирующим вектором. Она выбирается
из различных соображений и может представлять собой секретную константу или набор случайных данных (выборку даты и времени, например).
При таком подходе свойства хэш-функции полностью определяются свойствами одношаговой сжимающей функции.
Выделяют два важных вида криптографических хэш-функций — ключевые и бесключевые. Ключевые хэш-функции называют кодами аутентификации сообщений. Они дают возможность без дополнительных средств гарантировать как правильность источника данных, так и целостность данных в системах с доверяющими друг другу пользователями.
Бесключевые хэш-функции называются кодами обнаружения ошибок. Они дают возможность с помощью дополнительных средств (шифрования, например) гарантировать целостность данных. Эти хэш-функции могут применяться в системах как с доверяющими, так и не доверяющими друг другу пользователями.
Как я уже говорил основным требованием к хэш-функциям является равномерность распределения их значений при случайном выборе значений аргумента. Для криптографических хеш-функций также важно, чтобы при малейшем изменении аргумента значение функции сильно изменялось. Это называется лавинным эффектом.
К ключевым функциям хэширования предъявляются следующие требования:
— невозможность фабрикации,
— невозможность модификации.
Первое требование означает высокую сложность подбора сообщения с правильным значением свертки. Второе — высокую сложность подбора для заданного сообщения с известным значением свертки другого сообщения с правильным значением свертки.
К бесключевым функциям предъявляют требования:
— однонаправленность,
— устойчивость к коллизиям,
— устойчивость к нахождению второго прообраза.
Под однонаправленностью понимают высокую сложность нахождения сообщения по заданному значению свертки. Следует заметить что на данный момент нет используемых хэш-функций с доказанной однонаправленностью.
Под устойчивостью к коллизиям понимают сложность нахождения пары сообщений с одинаковыми значениями свертки. Обычно именно нахождение способа построения коллизий криптоаналитиками служит первым сигналом устаревания алгоритма и необходимости его скорой замены.
Под устойчивостью к нахождению второго прообраза понимают сложность нахождения второго сообщения с тем же значением свертки для заданного сообщения с известным значением свертки.
Это была теоретическая часть, которая пригодится нам в дальнейшем…
Алгоритмы CRC16/32 — контрольная сумма (не криптографическое преобразование).
Алгоритмы MD2/4/5/6. Являются творением Рона Райвеста, одного из авторов алгоритма RSA.
Алгоритм MD5 имел некогда большую популярность, но первые предпосылки взлома появились еще в конце девяностых, и сейчас его популярность стремительно падает.
Алгоритм MD6 — очень интересный с конструктивной точки зрения алгоритм. Он выдвигался на конкурс SHA-3, но, к сожалению, авторы не успели довести его до кондиции, и в списке кандидатов, прошедших во второй раунд этот алгоритм отсутствует.
Алгоритмы линейки SHA Широко распространенные сейчас алгоритмы. Идет активный переход от SHA-1 к стандартам версии SHA-2. SHA-2 — собирательное название алгоритмов SHA224, SHA256, SHA384 и SHA512. SHA224 и SHA384 являются по сути аналогами SHA256 и SHA512 соответственно, только после расчета свертки часть информации в ней отбрасывается. Использовать их стоит лишь для обеспечения совместимости с оборудованием старых моделей.
Российский стандарт — ГОСТ 34.11-94.
